Llevamos meses envueltos en la crisis de la memoria, pero quizás haya una salida. Investigación de Google de la semana pasada publicó un estudio en el que reveló una técnica llamada TurboQuant. Se trata de un algoritmo de compresión capaz de comprimir la memoria de trabajo de los modelos de IA hasta seis veces sin pérdida apreciable de calidad o rendimiento. Una gran noticia para los usuarios finales, que ven una luz al final del túnel, pero una pésima noticia para los fabricantes, para quienes esta época dorada puede terminar.
Expliquemos qué es la caché KV.. Para entender TurboQuant hay que entender cuál es esa memoria que logra comprimir. Cuando un modelo de lenguaje procesa una conversación larga, necesita recordar el contexto. Cada token que se procesa se almacena en la llamada caché KV, un tipo de memoria de trabajo que crece a medida que charlamos. Cuanto más larga sea la conversación, más memoria necesitará el modelo.
Comprimir lo que es un gerundio. Es uno de los principales cuellos de botella en la etapa de inferencia de la IA (es decir, cuando utilizamos los modelos), y uno de los motivos por los que los centros de datos necesitan tanta RAM o memoria HBM. TurboQuant utiliza un método de cuantificación vectorial para comprimir este caché manteniendo la precisión del modelo.
Flautista. Nada más aparecer este estudio de Google comenzaron las analogías con la trama de la serie ‘Silicon Valley’. En él, la startup ficticia de la trama logró desarrollar un algoritmo de compresión extraordinariamente eficiente llamado Pied Piper que amenazaba con revolucionar la industria tecnológica. Estos días aparecieron en las redes sociales múltiples referencias a la serie, que ya había sido calificada de visionaria por reflejar lo que sucede con espectacular exactitud incluso cuando la serie era una comedia.
Seis veces menos memoria. El artículo de Google Research afirma que este método es capaz de reducir la caché KV seis veces sin una diferencia apreciable en el rendimiento en conversaciones largas. Los investigadores presentarán sus resultados en un evento el próximo mes y explicarán los dos métodos que permiten ponerlo en práctica. Si confirman lo que ya han adelantado, las implicaciones son enormes: menos memoria para inferencia significa que los centros de datos pueden hacer lo mismo con mucho menos hardware/memoria.
El momento DeepSeek de Google. El descubrimiento hace que algunos analistas lo llamen el «momento DeepSeek» de Google. Hace un año, la startup china DeepSeek lanzó un modelo de IA que competía con los mejores pero cuyo desarrollo había costado mucho menos. Eso sacudió a la industria y ahora volvemos a un logro técnico que apunta a lo mismo. En IA, hacer lo mismo con menos es crucial, dados los enormes recursos que requiere esta tecnología. Hay quienes ya haber hecho evidencia preliminares con TurboQuant y he confirmado que el método realmente funciona.
Micron, Samsung y SK Hynix lo pagan caro. El impacto de esta técnica puede ser enorme, y así se ha empezado a notar ya en las valoraciones bursátiles de los fabricantes de memorias DRAM y de HBM. Empresas como Micron, Samsung, SK Hynix, SanDisk y Kioxia cayeron notablemente la semana pasada desde sus máximos recientes. El 18 de marzo rondaba los 471 dólares, y hoy sus acciones están a 357 dólares, una asombrosa caída del 24,2%. Lo mismo ha ocurrido con el resto de fabricantes, que ya venían cayendo desde esa fecha, pero han acelerado esa caída con el lanzamiento de TurboQuant.
Pero. En teoría, la técnica solo se puede aplicar a la fase de inferencia, pero la fase de entrenamiento de los modelos de IA no se ve afectada por esta técnica de compresión. Por lo tanto, todavía se necesitarán grandes cantidades de memoria durante la fase de entrenamiento. Además, habrá que esperar a que las empresas de IA realmente empiecen a aplicar dicho sistema si se confirma que funciona, y será entonces cuando podremos ver el impacto real. En teoría, esto dará mucho margen de maniobra a las grandes tecnologías, que podrán reducir aún más los precios de los tokens, pero aún está por ver si lo logran.
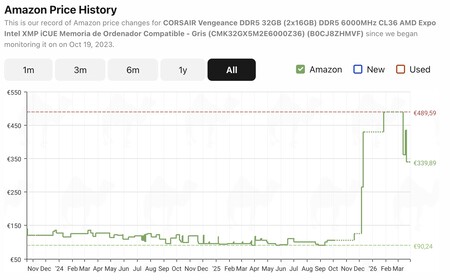
Las memorias RAM bajan de precio. El impacto de TurboQuant también ha sido claro en los precios de los módulos de memoria, que han bajado sensiblemente de precio. Por ejemplo, los módulos Corsair Vengeance DDR5 32 GB 6000MHz (2x16GB) estaban a 489,59 euros en Amazon hasta hace unas semanas según CamelCamelCamel, pero ahora mismo están a 339,89 euros, un descuento notable. Es cierto que no todos los componentes están cayendo por igual, pero sí hay casos en los que parece que se están produciendo reducciones.
En | La crisis de la RAM está echando por tierra todos los planes de Valve con su Steam Machine







{kind=link}